
"Big Data" to ułuda? Przyrost wartościowych danych nie nadąża za możliwościami sprzętu

Zanim popularnym tematem technologicznych zainteresowań w łonie dyscyplin humanistycznych stała się "sztuczna inteligencja", było nim "big data". Termin ten nie jest nowy, pochodzi jeszcze z lat 90., ale od około 2010 roku zaczął pojawiać się w opracowaniach naukowych poświęconych kulturze i społeczeństwu. Dziś warto zastanowić się, czy rzeczywiście jest przydatny, tym bardziej, że nawet branża IT zwraca uwagę na jego ograniczenia.
Wpływ na popularność "big data" w humanistyce miało z pewnością uruchomienie Google Ngram Viewer (2010) i wcześniejszy głośny artykuł Chrisa Andersona w "Wired" (2008), w którym przekonywano nas, że wobec szerokiej dostępności danych fenomeny społeczne badać będzie można empirycznie, bez przybliżeń i teorii: skoro dostępne są dane o wszystkim, po co budować modele? Aby coś zbadać, wystarczy już tylko policzyć. Także badacze, którzy stali za stworzeniem korpusu z Google Books (tym właśnie jest Ngram Viewer), podkreślali przecież przełomowość wielkoskalowych danych w badaniach kultury: stworzyli nawet opisujące je pojęcie kulturomiki - Culturomics.
Potem jednak przyszła "rewolucja ai" i wszyscy pobiegli za piłką w inny róg boiska. Oczywiście, to nie jest tak, że "big data" przestała być użytecznym terminem. Statystyki z bazy Scopus pokazują, że także w pracach z dziedzin humanistycznych jest ono używane.
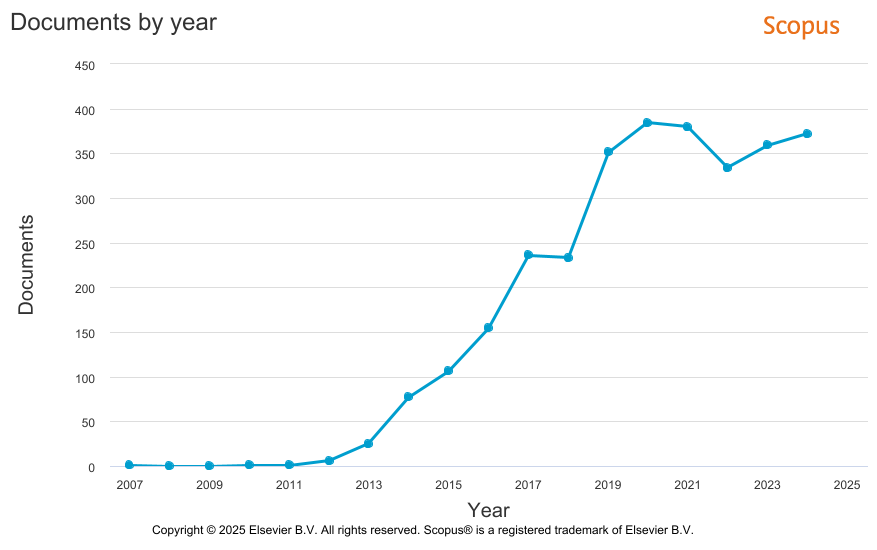 Liczba tekstów naukowych, w których abstraktach, tytułach lub słowach kluczowych występuje fraza "big data" w bazie Scopus, (n = 3020)
Liczba tekstów naukowych, w których abstraktach, tytułach lub słowach kluczowych występuje fraza "big data" w bazie Scopus, (n = 3020)
Kiedy jednak zajrzymy do tych tekstów, zobaczymy, że skala danych, jakie wykorzystuje się w poszczególnych opracowaniach, nie jest specjalnie imponująca. Oto kilka przykładów (uwaga na cherry picking!):
- Big Data Analysis of ‘VTuber’ Perceptions in South Korea: Insights for the Virtual YouTuber Industry (DOI: 10.3390/journalmedia5040105, 2024) - analiza obejmuje nieco ponad 57 tys. fragmentów z mediów i prasy,
- The Gaza War: Text Analysis (DOI: 10.30564/fls.v6i6.7638, 2024) - analiza 40 artykułów z portalu newsowego BBC,
- Big borges: What can big data show about a classic writer on social networks? (DOI: 10.1515/9783110753523-013, 2023) - analiza ponad 205 tys. tweetów.
Nie mamy tu czasu na głębsze spojrzenie, ale wiadomo, o co chodzi. Część z tekstów zajmuje się "big data" teoretycznie, część może i nawet praktycznie stosuje kojarzone z nią metody, chociaż skala danych badawczych jest stosunkowo nieduża. Powiedzmy sobie szczerze, że 200 tys. tweetów czy 57 tys. tekstów prasowych to nie jest skala, z którą nie mógłby poradzić sobie zwykły komputer biurowy.
Czy współczesny status "big data" nie przypomina przypadkiem strzelania z armaty do wróbli? Sugerować to mogą też sygnały z branży IT. Oto rok temu Hannes Mühleisen, założyciel i szef DuckDB Labs, na konferencji GOTO Amsterdam wskazał na pewien ciekawy problem:
- "big data" w korporacjach IT wiąże się ze skalowalnością - bazy danych i oprogramowanie je obsługujące musi być przygotowane na dużą objętość danych. Przygotowanie takiego systemu to oczywiście duże koszty,
- tymczasem jeśli zatrudnić całą pracującą populację Holandii (około 10 milionów ludzi) i kazać im pisać przez cały rok z prędkością 200 znaków na minutę, wygenerowałoby to około 200 terabajtów danych. Po kompresji byłoby to 60 terabajtów, co da się zmieścić maksymalnie na 2-3 dyskach zewnętrznych. Skala realnie dostępnych danych jest ograniczona (to bardzo ważna uwaga także dla humanistycznych badaczy i badaczek),
- zwykłe komputery potrafią coraz więcej. Jak mówił Mühleisen, chip Apple M3 ma 400 MB pamięci podręcznej i przepustowość pamięci RAM 400 gigabajtów na sekundę, dyski SSD są też coraz szybsze.
Rok później na blogu firmowym DuckDB ten sam Mühleisen przynaje już, że rzeczywista wielkość "użytecznych" zbiorów danych często nie jest tak duża, żeby korzystać z zaawansowanych rozwiązań "big data". Zdaniem Mühleisen, branża przeszacowała zapotrzebowanie na tego typu usługi. Rynek może się mylić? Niemożliwe ;)
Dlatego jeśli nie analizujemy akurat danych cząsteczek w CERN albo nie pracujemy przy analityce systemu PESEL, nie ma sensu, żeby odwoływać się do "big data", szczególnie w badaniach historycznych czy kulturowych, gdzie skala zbiorów może być duża, ale jednak nie aż tak duża.