
Protokół GrAImes do oceny tekstów literackich i prozy generatywnej

Czy tego chcemy, czy nie, maszynowe generowanie tekstu jest już na tym poziomie, że może z powodzeniem imitować literaturę. A skoro tak, to potrzebne są narzędzia, aby taką generatywną literaturę skutecznie oceniać.
W 2024 roku opublikowano badanie (DOI: 10.1038/s41598-024-76900-1), w którym wykazano, że osoby bez specjalistycznego przygotowania nie potrafią wiarygodnie rozróżnić wierszy wytworzonych przez AI od tych napisanych przez znanych poetów. Już w samym abstrakcie tego artykułu podkreślano problem wynikający z błędnego podejścia do analizy:
Odkryliśmy, że wiersze generowane przez AI były oceniane korzystniej pod względem takich cech jak rytm i piękno, co przyczyniało się do ich błędnej identyfikacji jako utworów ludzkich. Wyniki naszych badań sugerują, że uczestnicy posługiwali się wspólnymi, lecz błędnymi heurystykami w próbach odróżnienia poezji AI od ludzkiej poezji: prostota wierszy generowanych przez AI mogła być łatwiejsza do zrozumienia dla niespecjalistów, co prowadziło do preferowania poezji AI i błędnej interpretacji złożoności ludzkich wierszy jako chaotycznych tekstów stworzonych przez sztuczną inteligencję.
Badanie to ostatecznie dowiodło nie tyle jakości poezji tworzonej przez sztuczną inteligencję, co błędnego rozumienia przez ludzi tego, czym poezja powinna być, a czym na pewno nie jest.
Rok później w tekście Can Artificial Intelligence Write Like Borges? An Evaluation Protocol for Spanish Microfiction (DOI: 10.48550/arXiv.2506.08172, 2025) otrzymujemy propozycję pewnego schematu (protokołu) oceny literatury (mikrofikcji), który powinien sprawdzać się też w ocenianiu prozy generatywnej. Protokół GrAImes (Grading AI and Human Microfiction Evaluation System) wziął swoją nazwę od Josepha E. Grimesa (ur. 1922), jednego z pionierów maszynowej analizy języka i twórcy pierwszego systemu generowania prozy.
GrAImes jako pewien szablon oceny tekstów literackich ma brać pod uwagę nie tylko ich spójność językową czy logiczną (co może być dużym wyzwaniem dla prozy generowanej maszynowo), ale też wartość literacką, estetyczną i kulturową. Metafory, symbolika czy kreatywność stylistyczna muszą być w takiej analizie wzięte pod uwagę. Protokół zbudowano na podstawie doświadczeń z procesów redakcyjnych w czasopismach literackich. Na tym etapie dostosowany jest przede wszystkim do mikrofikcji - krótkich opowiadań do 300 słów, których zwięzłość ułatwia proces oceny. Generowanie takich tekstów jest też dla modeli językowych łatwiejszym zadaniem niż przygotowywanie obszernych opowiadań.
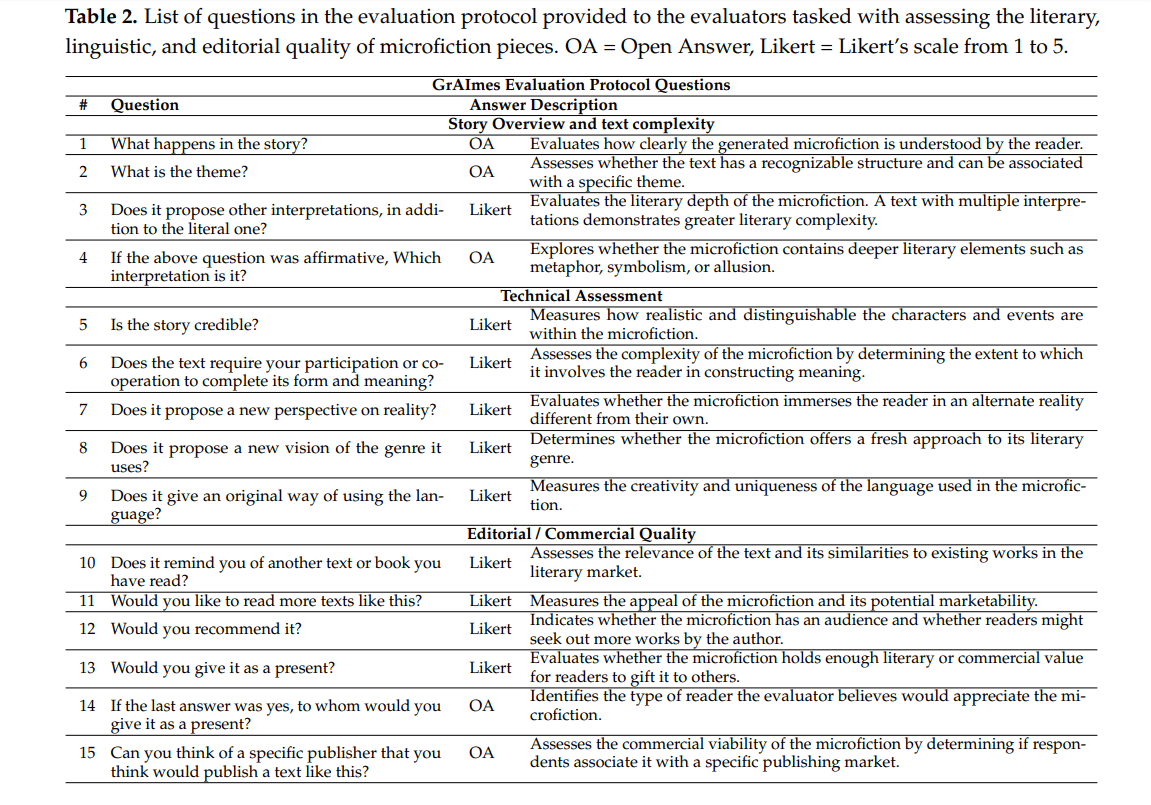
Protokół GrAImes to ostatecznie 15 pytań wokół analizowanego tekstu. Część z nich to pytania otwarte, część zamknięte, w których odpowiada się w pięciostopniowej skali Likerta.
Jeśli spojrzymy z uwagą na te pytania, zobaczymy, że odnoszą się one także do społecznego wymiaru literatury. Czy oceniany tekst jest warty polecenia? Czy mógłby być dobrym pomysłem na prezent (już w postaci książki)? Czy można wskazać wydawcę, który mógłby wydać ten tekst? Czy chcielibyśmy czytać więcej tekstów tego typu?
Być może entuzjastyczne głosy o tym, że ChatGPT i podobne rozwiązania mogą wytwarzać literaturę bazują na tym, że interesuje nas wyłącznie fabuła, zgodność logiczna i językowa takich wytworów. Jednak literatura to coś więcej niż pisarska sprawność.
Protokół GrAImes przetestowano w dwóch turach: w pierwszej wykorzystali go eksperci i ekspertki w zakresie literatury hiszpańskojęzycznej do oceny tekstów pisanych przez ludzi. W drugiej grupa entuzjastów literatury oceniała teksty generowane przez ChatGPT-3.5 oraz Monterroso (GPT-2, wytrenowany dodatkowo na korpusie hiszpańskich mikroopowiadań).
Okazało się, że ocena tekstów generowanych przez AI i tekstów pisanych przez ludzi znacząco różni się w zależności od doświadczenia i nawyków czytelniczych oceniających. Eksperci koncentrowali się na głębi, oryginalności, złożoności tematycznej czy obecności międzytekstowych odniesień w prozie, fani literatury zwracali uwagę przede wszystkim na czytelność, wartość rozrywkową i przekaz emocjonalny tych tekstów.
Testy takie jak Alfa Cronbacha czy wyznaczony współczynnik korelacji wewnątrzklasowej (ICC) wykazały wysoką spójność odpowiedzi dla wielu pytań. Oceny ekspertów były zbliżone, oceny fanów bardziej zróżnicowane, ostatecznie jednak wszystko wskazuje na to, że protokół GrAImes sprawdza się lepiej w profesjonalnej ocenie literackiej. Należy przy tym wziąć pod uwagę, że grupa testująca protokół była niewielka, a testowano oceny mikrofikcji w języku hiszpańskim. Jak czytamy, protokół ma być dalej rozwijany i optymalizowany, ponieważ w przypadku części pytań niska lub nawet negatywna wartość ICC ujawniła potrzebę ich ponownego przeredagowania czy doprecyzowania.
Autor: redakcja