
ChatGPT skutecznie wyodrębnił dane z biogramów Polskiego Słownika Biograficznego

Jedną z wad dyskusji o “sztucznej inteligencji” są ogólne pytania, na które nie da się skutecznie odpowiedzieć. Pytania o to, czy AI zabierze nam pracę, zrewolucjonizuje twórczość albo czy ma świadomość nie służą być może niczemu innemu jak pozycjonowaniu się w debacie technologicznej i pokazywaniu, że jest się na bieżąco, bez ponoszenia tych wszystkich kosztów sięgania po szczegóły, dane i studia przypadku.
Takim interesującym studium przypadku, które rzeczywiście mówi nam coś o potencjale sztucznej inteligencji, jest opublikowany w marcu 2025 przez badaczy z IH PAN artykuł o efektywności ChatGPT (DOI: 10.1093/llc/fqaf014). Mamy tam nie tylko konkretny test rozwiązań udostępnianych przez OpenAI, ale też lokalny kontekst: za pomocą ChatGPT przetwarzane są biografie z Polskiego Słownika Biograficznego. Testuje się więc globalne narzędzie w konkretnych uwarunkowaniach: języku, stylach pisania, specyfice treści. Takimi badaniami warto się zainteresować, bo rzeczywiście mówią coś o możliwościach sztucznej inteligencji.
Celem badania było sprawdzenie, jak skutecznie ChatGPT jest w stanie wyodrębnić z tekstu 250 biogramów PSB podstawowe informacje o opisywanych tam osobach. ChatGPT bazuje na ogólnym dużym modelu językowym (LLM), więc istnieje zasadne pytanie o to, czy da się go użyć do takiego specyficznego zadania. To przy tym jedno z podstawowych zastosowań przetwarzania języka naturalnego - NER (Named Entity Recognition). W przypadku badania warszawskich historyków chodziło jednak nie tylko o skuteczne wyodrębnienie podstawowych danych biograficznych (takich jak miejsca i daty urodzenia i śmierci), ale też danych pozwalających na zbudowanie relacji między osobami - na przykład informacji o rodzinie i krewnych, współpracownikach czy instytucjach, z którymi te osoby były związane. Efektem przetworzenia tekstów biogramów miały być dane w postaci JSON, nadające się do dalszego wykorzystania, np. przy stworzeniu wizualizacji sieciowej.
Zadania dla ChatGPT wyrażono w języku naturalnym, a zapytania wysyłano do oficjalnego API z wykorzystaniem Pythona. Kod źródłowy i dane badawcze są udostępnione. Warto zwrócić uwagę, że dla ograniczenia kosztów badania (korzystanie z API jest płatne), ograniczono treść analizowanych biografii do kilkunastu pierwszych i ostatnich linijek oryginalnego tekstu.
Jakie były efekty analizy?
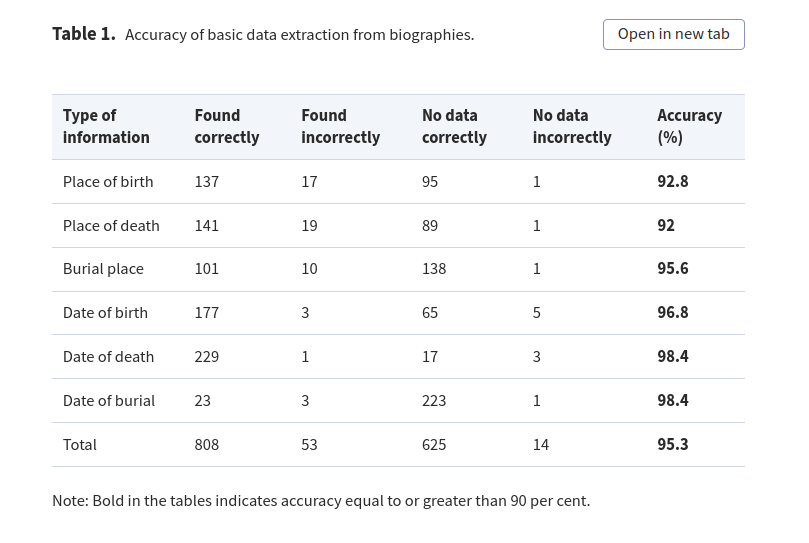
Kolumna No data correctly oznacza, że model prawidłowo nie wyodrębnił wyszukiwanych informacji, ponieważ ich nie było w tekście źródłowym. Przykładowo, dla wielu biogramów postaci z okresu średniowiecza brakuje danych na temat daty czy miejsca urodzenia lub śmierci.
Błędne odpowiedzi wynikają z faktu, że model zinterpretował miejsce pochodzenia bohatera lub jego rodziny jako miejsce urodzenia, co niekoniecznie dowodzi, że rzeczywiście się tam urodził. Podobnie średniowieczne nazwiska (np. Szymon ze Stobnicy) były często traktowane jako wskazanie miejsca urodzenia, ponieważ w języku polskim „z/ze” oznacza dokładnie „z” (czyli „pochodzący z”). Gdyby wyeliminować tego rodzaju błędy, skuteczność wynosiłaby około 99 procent.
Dla wszystkich zadań w ramach badania wykorzystanie ChatGPT okazało się bardzo skuteczne. Autorzy opracowania podkreślają, że
LLM-y prawdopodobnie nie zastąpią wcześniejszych metod stosowanych w przetwarzaniu języka naturalnego, ale w przypadku automatycznego wydobywania informacji z tekstów stanowią narzędzie, które daje nadzieję na znaczący postęp. Ich wykorzystanie może umożliwić automatyzację i przyspieszenie wcześniej trudnych do przeprowadzenia prac. Zaletą zastosowania LLM-a jest to, że potrafi on przetworzyć dużą liczbę niestrukturyzowanych tekstów na dane strukturalne w rozsądnym czasie — zespołowi kilku historyków zajęłoby to kilka lat pracy, aby opracować prawie 30 000 biogramów PSB istniejących obecnie w celu pozyskania danych o postaciach historycznych (dla porównania: weryfikacja próbki 250 biogramów zajęła kilka miesięcy). Zgodnie z opisaną powyżej procedurą, model językowy oparty na wcześniej przygotowanych promptach wykona większość tego zadania (większość, ponieważ konieczna jest wspomniana weryfikacja) w ciągu kilkudziesięciu godzin.
Otwartym pozostaje pytanie, jak bardzo bylibyśmy w stanie zaufać takiej automatycznej ekstrakcji informacji biograficznych. Weryfikacja dużego korpusu tekstów byłaby długa i kosztowna. Skoro byłaby również niezbędna, jaki jest sens przetwarzania w ten sposób tekstów źródłowych?
Na te wątpliwości odpowiedział mi Piotr Jaskulski, jeden z autorów omawianego badania:
Kiedy zaczynaliśmy próby wydobywania informacji z PSB, były to czasy "przed ChatemGPT" i stosowane były bardziej tradycyjne metody NLP (do wyszukiwania relacji semantycznych w zdaniach, przygotowane przez Clarin-PL), wówczas szczególnie zależało nam na wyszukaniu związków rodzinnych, relacji między postaciami występującymi w biogramach. Niestety poprawność tych metod była niewielka - testy pokazały około 12% poprawnie wskazanych relacji, zdecydowanie poniżej progu, w którym takie zastosowanie byłoby sensowne.
Kiedy pojawiły się duże modele językowe, przyzwoicie radzące sobie z językiem polskim, trudno było nie skorzystać z okazji i nie wypróbować ich do naszych celów. Wyniki tego testu zostały przedstawione w artykule. Zależnie od rodzaju informacji, są one nieco lepsze lub dużo lepsze, ale oczywiście nie bezbłędne. Można oczywiście brać poprawkę na moment wykonywania testów, artykuł wyszedł w marcu 2025, ale testy przeprowadzane były mniej więcej jesienią 2023. Obecne modele mogłyby dać lepszy wynik, ale o bezbłędności nie będzie (raczej) mowy nigdy.
Wydaje się przy tym, że naprawdę nie ma alternatywy dla metod maszynowych w tego typu zadaniach:
Mogę też odwrócić pytanie, co jeśli nie stosować metod automatycznej ekstracji? Szacowaliśmy kiedyś czas, który trzeba by poświęcić na manualne wydobywanie wiedzy z biogramów PSB (obecnie to prawie 30 tys. biogramów i rośnie). I było to chyba 25-30 roboczo-lat, wydaje się więc, że nie ma alternatywy dla automatyzacji takich prac. Dziś daje ona dużo lepsze wyniki niż 4 lata temu a modele, metody automatycznej ekstrakcji, oraz metody automatycznej weryfikacji są cały czas udoskonalane.
Reliability of large language models as a tool for knowledge extraction from biographical dictionaries: the case of the Polish Biographical Dictionary (DOI: 10.1093/llc/fqaf014, 2025)
Autor: redakcja