
Oddolna archiwizacja platform cyfrowych - Flickr i projekt Data Lifeboat

Trudno planować pełną archiwizację, kiedy twoja platforma przechowuje i udostępnia miliardy zdjęć. Może zamiast bezskutecznie starać się o zabezpieczenie wszystkich zasobów warto pozwolić użytkownikom, żeby samodzielnie archiwizowali te, które są dla nich ważne? Taką zdecentralizowaną archiwizację proponuje projekt Data Lifeboat, rozwijany przez Flickr Foundation.
Flickr.com powstał w 2004 roku. To jedna z najstarszych platform społecznościowych w sieci. Dziś znajduje się tam dziesiątki miliardów zdjęć, przesłanych przez miliony ludzi z całego świata. Znajdziemy tam zdjęcia każdego miasta i większości znanych miejsc, a także codzienne, intymne obrazy naszego życia. To jedna z największych kolekcji, jakie ludzkość kiedykolwiek zgromadziła. Wśród tego ogromnego zbioru znajduje się niezliczona ilość zdjęć, które naprawdę warto zachować dla przyszłych pokoleń. Jednak jak więc zapewnić im trwałe dziedzictwo i dostępność? Całość zasobów Flickr jest po prostu zbyt duża, by mogło ją pomieścić i zadbać o nią jedno archiwum. Wiemy, że nie jesteśmy w stanie ocalić wszystkiego - i nie powinniśmy tego robić. Dlatego właśnie stworzyliśmy Data Lifeboat.
Oddolne tworzenie łodzi ratunkowych dla danych z Flickra ma być odpowiedzią na sytuację, w której platforma przestaje działać, a wszystkie publikowane na niej zdjęcia i metadane nie są już dostępne.
Przyjrzyjmy się krótko założeniom tego projektu:
- każda pobrana paczka archiwalna jest samowystarczalna (brak zależności, zero zewnętrznych plików, dynamicznie pobieranych z serwerów Flickr, prosty i czysty HTML, zgodne ze standardami JavaScript bez zewnętrznych bibliotek),
- minimalistyczne założenia co do kodu i bibliotek JS powodują, że paczka archiwalna jest dostosowana do niskotechnologicznego przetrwania - nie wiemy, jakie technologie programistyczne i sprzętowe pojawią się w przyszłości i czy współczesne będą jeszcze aktualne. Dlatego warto budować archiwum na podstawowych rozwiązaniach, które da się skutecznie wykorzystać za 50 czy 150 lat,
- elastyczność - paczkę archiwalną można swobodnie wykorzystywać, przetwarzać, importować do własnych systemów,
- czytelny schemat obejmujący zasoby (zdjęcia) i metadane. W pliku
READMEwpisujemy wiadomość dla przyszłości (note to the future), w której informujemy, dlaczego stworzono kolekcję, kto ją stworzył i co chcielibyśmy, żeby się z nią dalej stało,
Strasznie podoba mi się wstępne założenie, że nie da się wszystkiego zarchiwizować. Dlatego zamiast autorytatywnie i odgórnie wybierać to, co powinno być zabezpieczone, można oddać te decyzje ludziom. Oczywiście, taka strategia ma swoje wady: czy rzeczywiście rozproszone pomiędzy użytkowników archiwum może być skutecznym archiwum? Czy bez kontroli nad tym, co dzieje się z paczkami archiwalnymi po pobraniu ich na dyski użytkowników, można planować jakiekolwiek działania np. z rekonstrukcją zbiorów?
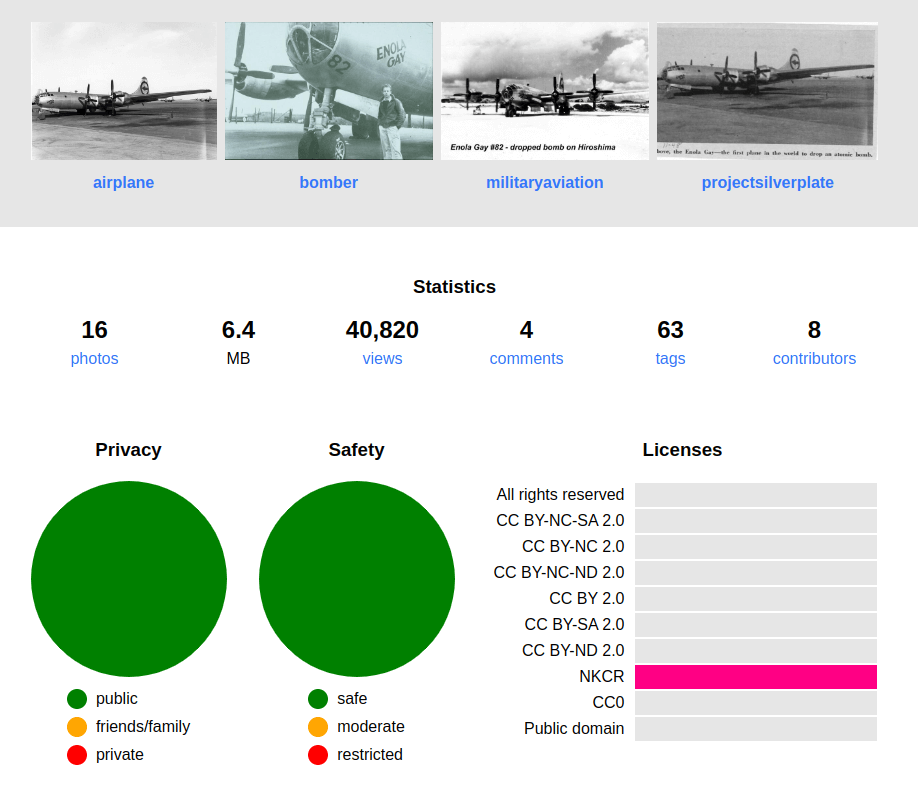 Fragment zawartości paczki archiwalnej Data Lifeboat
Fragment zawartości paczki archiwalnej Data Lifeboat
Wydaje się, że to ryzyko ograniczać ma oferta Fundacji Flickra dla dla instytucji, które oficjalnie udostępniają swoje zbiory w tej platformie. Oto przygotowywana jest opcja archiwizacji w chmurze w ramach projektu LOCKSS (Lots Of Copies Keep Stuff Safe).
Projekt Lifeboat rozwijany jest dzięki finansowaniu Mellon Foundation i państwowemu funduszowi National Endowment for the Humanities (NEH).
Data Lifeboat - strona domowa programu
Data Lifeboat - prezentacja rozwiązań
Designing a Data Lifeboat - szczegółowy opis programu
Building a “Data Lifeboat” for Flickr - raport (2025)
LOCKSS - Lots Of Copies Keep Stuff Safe
Autor: redakcja